制限ボルツマンマシンとは #
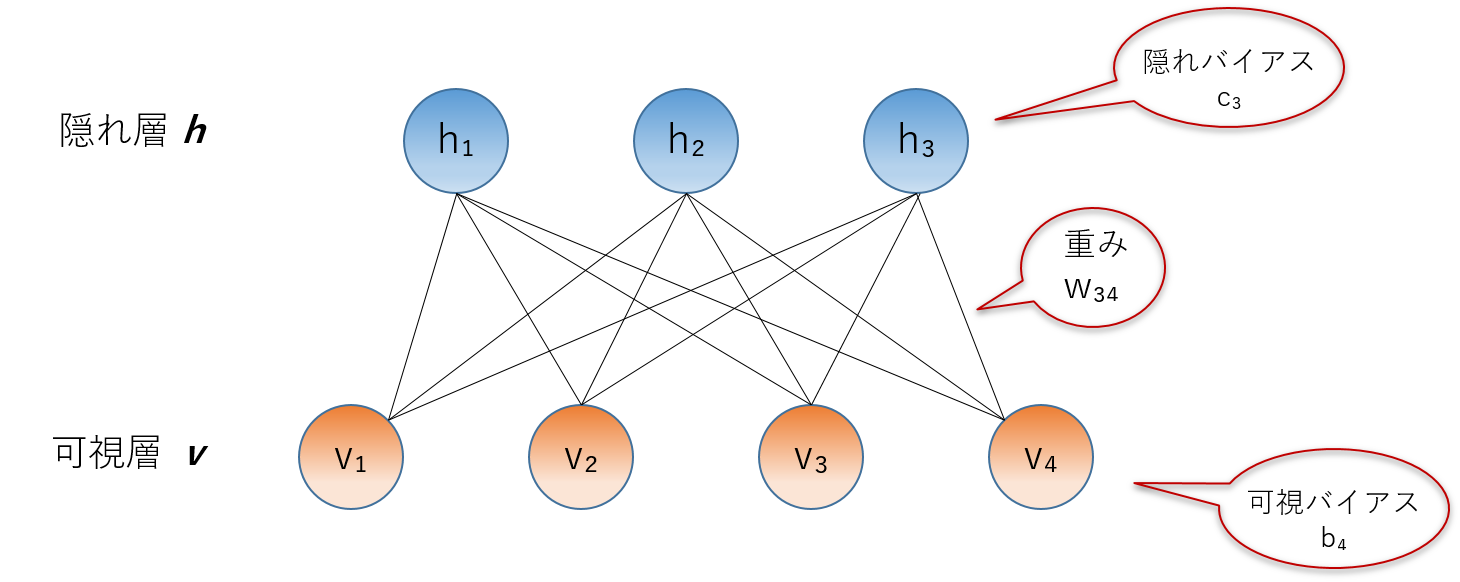
制限ボルツマンマシン(Restricted Boltzmann Machine, 以下RBM)とは、図のような無向グラフで表現される確率モデルで、その名のとおりグラフの構造に制限があるモデルです。グラフは可視層と隠れ層から成る2部グラフであり、同じ層内での相互作用はありません。また各ユニットに対応したバイアス \(b_i,c_j\) 、エッジに対応した重み \(w_{ij}\) をもちます。 以下、これらのパラメータをまとめて \(\theta = \left(\boldsymbol{b,c,w}\right)\) と書きます。
このグラフに対し、次のエネルギー関数が定義されます。 \[ E\left(\boldsymbol{v,h},\theta\right) = - \sum_i b_i v_i - \sum_j c_j h_j - \sum_{i,j} w_{ij} v_i h_j \]
\[ E\left(\boldsymbol{v,h},\theta\right) = - \boldsymbol{b}^{T} \boldsymbol{v} - \boldsymbol{c}^{T} \boldsymbol{h} - \boldsymbol{v}^{T} \boldsymbol{W} \boldsymbol{h} \] このエネルギー関数のもとで、制限ボルツマンマシンは次の確率分布を持つと定義されます。 \[ P\left(\boldsymbol{v,h}|\theta\right) = \frac{1}{Z\left(\theta\right)} \exp\left(-E\left(\boldsymbol{v,h},\theta\right)\right) \] このような確率分布をボルツマン分布と呼ぶことから、このモデルをボルツマンマシンと呼ぶようです。 \(Z\left(\theta\right)\) は規格化因子で、物理学の文脈では分配関数(partition function)と呼ばれるものです。
\[ Z\left(\theta\right) = \sum_{ \boldsymbol{v}} \sum_{ \boldsymbol{h} }\exp \left( \sum_i b_i v_i + \sum_j c_j h_j + \sum_{i,j} w_{ij} v_i h_j \right) \]条件付き独立性 #
RBMはそのグラフの構造上、一方の層を固定したときに他方の層の変数が条件付き独立性をもちます。
可視層が固定されているときの、隠れ層の条件付き確率の式は次のようになります。 \[ P\left(h_j = 1|\boldsymbol{v},\theta\right) = sigmoid \left(c_j + \boldsymbol{v}^T \boldsymbol{W} \right) = \frac{1}{1 + \exp \left(- c_j - \sum_i v_i W_{ij} \right)} \]
このように、可視層すべての値とエッジの重みとの内積をシグモイド関数に入れたもので、 この確率で1となる二項分布によって隠れ層の取る値の組み合わせが決まります。この点から、ニューラルネットワークのような確定的にノードの値が決まる機械学習モデルとは異なる、確率的機械学習モデルであるといえます。
制限ボルツマンマシンの学習 #
RBMの学習とは、与えられた訓練データをもっともうまく説明しそうなパラメータをもつモデルを作成することです。訓練データを可視層に入れると、隠れ層のフィルタを通して再び可視層に値が返ってきます。その結果を入力と比較し、最適な出力が得られる方向に勾配上昇によってパラメータを調整します。この最適化、そしてその結果の学習方程式の導出には最尤推定、あるいはカルバック・ライブラー(Kullback, Leibler )ダイバージェンスを用いる方法がありますが、ここではその詳細については踏み込みません。以下のような学習方程式が得られたものとして話をすすめます。
RBMの学習過程における、勾配上昇法によるパラメータ更新の式はこのようになります。 \[ \Delta b_i = \eta \left( v_i^{\left(k\right)} - \langle v_i \rangle_{model} \right) \] \[ \Delta c_j = \eta \left(P\left(h_j=1|\boldsymbol{v^{\left(k\right)}},\theta\right) - \langle h_j \rangle_{model} \right) \] \[ \Delta w_{ij} = \eta \left( v_i^{\left(k\right)}P\left(h_j=1|\boldsymbol{v^{\left(k\right)}},\theta\right) - \langle v_i h_j \rangle_{model} \right) \]
\(v_i^{\left(k\right)}\) はk番目の訓練データのi番目の成分を表します。 右辺の各項をポジティブフェイズ、ネガティブフェイズと呼びます。 それぞれ第1項は訓練データから得られる項、第2項はとりうる確率分布全体での期待値を表しています。RBM特有の条件付独立性から、第1項の計算が非常に簡単に行えます。
しかし、第2項はユニット数の増加によって計算量が指数関数的に増えてしまうという、いわゆる組み合わせ爆発の問題があり、直接計算するのは困難です。
第2項のモデル全体での期待値は以下のように計算されます。 \[ \langle v_i h_j \rangle_{model} = \sum_{v_1=0} ^1\sum_{v_2=0} ^1 \cdots \sum_{v_n=0} ^1 P\left( \boldsymbol{v}|\theta \right) \boldsymbol{v} \] このように、たとえば変数が100個だとすると \(2^{100}\) 回の計算が必要となり、 変数の増加に対し指数的に計算量が増えてしまいます。
そこでこの確率モデルのもとでなんらかのサンプリングを行い、その平均をとることによって期待値を近似してしまうという方法が考えられます。サンプリングには次で述べるようにいくつかの方法があります。
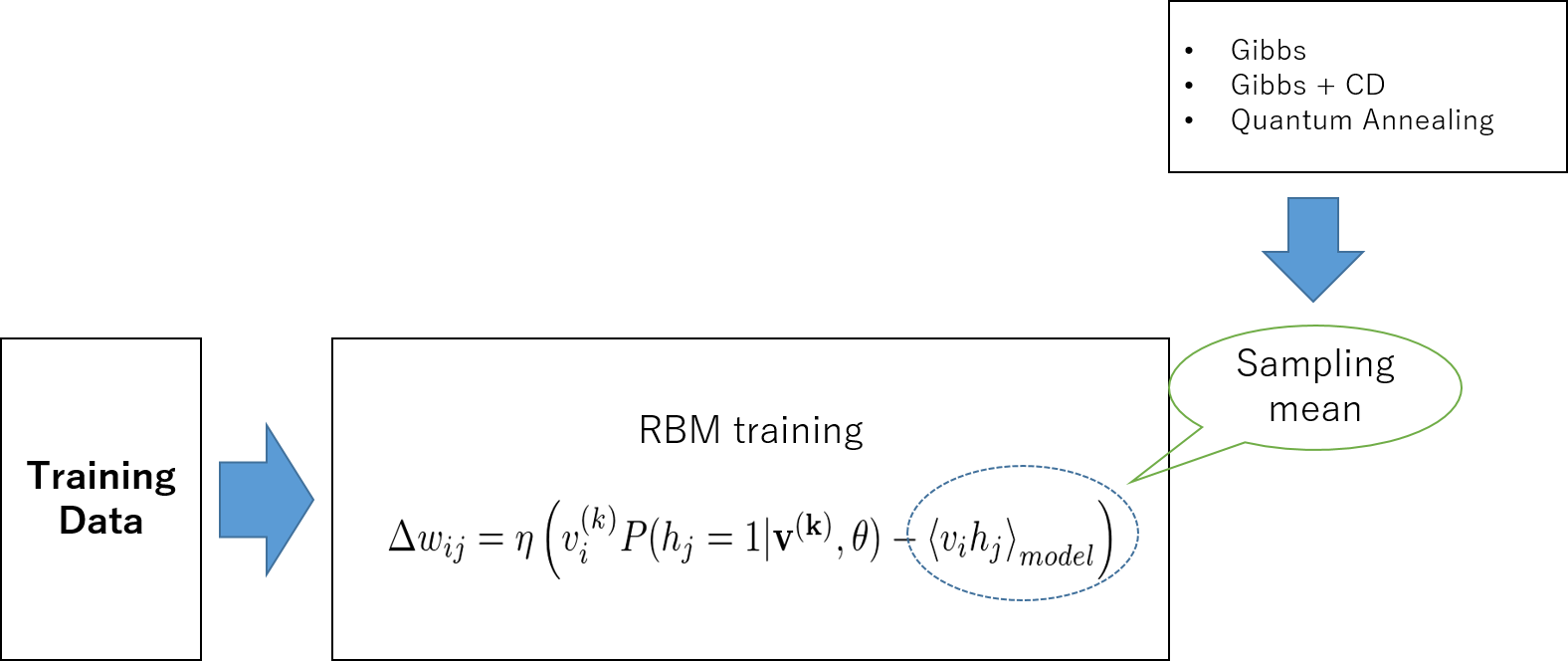
ギブスサンプリング #
RBMにおいてモデル全体での期待値の計算は困難だと述べました。そのために、乱数を用いたサンプリングにより期待値の近似値を得る方法をとります。つまり、調べたい分布 \(P\left(x\right)\) に対する期待値を得るために、その分布から独立な標本をN個生成し、その標本平均を期待値の代用とします。 \[ \langle F\left(x\right) \rangle = \frac{1}{N} \sum_{n=1} ^{N} F\left(x^{\left(n\right)}\right) \]
サンプリングにはMCMC(マルコフ連鎖モンテカルロ法)を用います。MCMCの中でも、特にギブスサンプリング(熱浴法)を用いるのが一般的です。 RBMにはそのグラフ構造に由来する条件つき独立性があります。 隠れ層の実現値が与えられたとき、可視層のサンプリングは独立な各成分 \(v_i\) を単純にそれぞれ \(P\left(v_i|\boldsymbol{h},\theta\right)\) からサンプルするだけでよいのです。 同様に、隠れ層のサンプリングも可視層の値を固定してやれば簡単に得られます。
具体的なギブスサンプリングの手順を説明します。
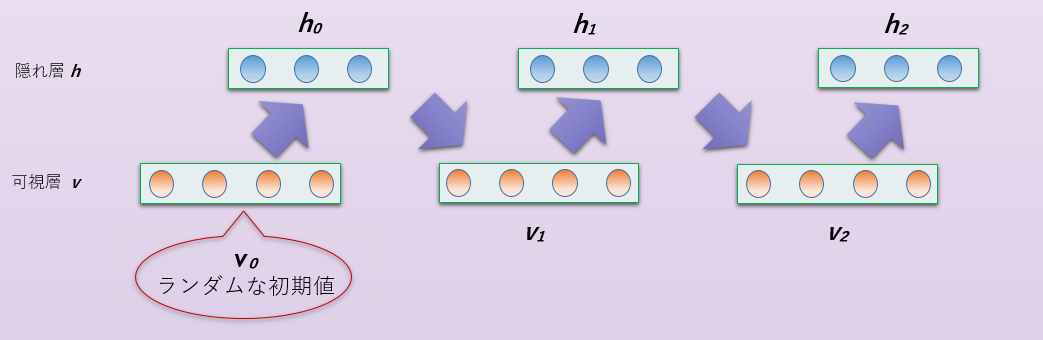
- 可視層の各ユニットの状態をランダムに初期化します。
- 隠れ層の各ユニットの値を、 \(P\left(h_j|\boldsymbol{v},\theta\right)\) の確率の二項分布からサンプリングします。
- (2)で得た隠れ層の状態から、次ステップの可視層の値を \(P\left(v_i|\boldsymbol{h},\theta\right)\) の確率の二項分布からサンプリングします。
- (2)と(3)を繰り返し、十分な時間(ステップ数)が経過した後の可視層、隠れ層の状態を1サンプルとして取得します。
- サンプル同士の相関が出ないように間隔をあけつつ、必要な数に達するまでサンプルを取得します。
このように可視層と隠れ層を交互にサンプリングするだけでマルコフ連鎖が実現されるのが、このモデルの有利な点といえるでしょう。
しかしながら、このサンプリング方法においても十分な時間を経てサンプルを取得するのには長い時間がかかってしまいます。この点を解消する処方として、次に述べるContrastive Divergence法というものが提案されました。
Contrastive Divergence法(CD法) #
この方法では、ギブスサンプリングに次の変更を加えます。
- 可視層の初期状態として、入力データ \(\boldsymbol{v_0}\) を用います。
- 隠れ層の各ユニットの値を、 \(P\left(h_j|\boldsymbol{v},\theta\right)\) の確率の二項分布からサンプリングします。
- (2)で得た隠れ層の状態から、次ステップの可視層の値を \(P\left(v_i|\boldsymbol{h},\theta\right)\) の確率の二項分布からサンプリングします。
- これを1回だけ行い、(3)で得た可視層の状態を用いて各期待値を計算します。
このように、通常のギブスサンプリングでは十分な時間が経過するまでマルコフ連鎖を続けたものを、 大胆にはじめの1回(あるいは数回とする方法もある)だけで終わることになります。 こうして得た近似値ですが、驚くべきことにうまくいくことが経験的に知られています。
アニーリングマシンを用いたサンプリング #
前述のようにMCMCを用いたサンプリングはボトルネックであり、そのためにContrastive Divergenceのような処方が提案され、実用度は大きく向上しました。
ここではそれをあえて用いず、アニーリングマシンにRBMの構造を埋め込み、最適化を行うことを考えます。これまでの方法がソフト的なサンプリングだとするなら、この手法はハードウェアによる実験的なサンプリングであるといえます。 RBMのグラフは二部グラフですが、埋め込みの手続きの簡単化のため今回は各ユニットが全結合であるとしました。このため実行できるユニット数は二部グラフで可能な数の半分までとなってしまいます。
学習済みRBMによるデータの再構成 #
訓練データとして以下の4つの20次元ベクトルを用いてRBMに学習させた。
視覚的に分かりやすいよう、0,1の成分を□,■で置き換えています。
 はじめにギブスサンプリングのみの結果と、ギブスサンプリング+CD法を用いたサンプリングでの学習結果を示します。
はじめにギブスサンプリングのみの結果と、ギブスサンプリング+CD法を用いたサンプリングでの学習結果を示します。
1. ギブスサンプリング #
学習率 \(\eta = 0.1,0.01,0.001\) でそれぞれ \(100,50,50\) 回ずつ学習を行いました。1回の学習ではギブスサンプリングでサンプルを100個とり、その標本平均を期待値の近似とします。
1回の学習にかかる時間はおよそ9秒でした。4つの学習データをそれぞれ1回ずつ学習させるのを1エポックという単位で数えるのですが、1エポックにかかる時間は36秒ということになります。全部で \(100+50+50=200\) エポックなので、すべて学習するのに約2時間かかったことになります。
学習後、訓練データと同じものを5回ずつ入力し、再現できるかどうかをテストした結果がこちら。
 ところどころにエラーも見られますが、ある程度再現できているといえるでしょう。
ただ、このサイズで2時間もかかってしまうのは、やはりギブスサンプリングでも計算量が多すぎることに起因しています。
ところどころにエラーも見られますが、ある程度再現できているといえるでしょう。
ただ、このサイズで2時間もかかってしまうのは、やはりギブスサンプリングでも計算量が多すぎることに起因しています。
2. Contrastive Divergence法 #
次に、訓練データは同じで、Contrastive Divergence法よる学習を行いました。
計算時間ですが、データ4つを1回ずつ学習させる1エポックにかかった時間が0.00152sです。
なんと10000倍以上も速くなりました。もちろんそれは当然のことで、10万回やっていたサンプリングを2回にしてしまったからです。このときの学習結果もほぼ変わらず、パラメータも収束しています。このような大胆な近似を行っても、サンプルの精度は落ちないというのが特徴です。

3. アニーリングマシン #
アニーリングマシンでの学習ですが、RBMのパラメータ更新時にアニーリングマシンと通信を行い、サンプリング結果をもらいます。 サンプリング部分以外の処理は通常のコンピュータで行っています。ですので、基本的な処理は1.ギブスサンプリングと同じです。
サンプリングの手順ですが、基本的にはグラフの重み、バイアスのパラメータ、サンプリング回数を 送るだけとなります。 現在の各パラメータ(重み、バイアス項)からQUBO多項式を作成します。 そして、QUBO多項式と欲しいサンプル数をアニーリングマシンに送り、その後返ってきた 結果からサンプリング期待値を計算します。
以上がアニーリングマシンを用いた学習の手順となります。 今回は、学習率0.1と0.01でそれぞれ100エポックずつ実行しました。 学習結果がこちら。

なんのためにやったのか #
1. RBMによる事前学習。 #
Deep Boltzmann MachineなどはRBMのスタックから作られる。 訓練データのみを与えた教師なしの事前学習に、このようなRBMの学習法が用いられる。
今後の課題 #
学習率のスケジューリングや適切なエポック数などは完全に手探り。 適切な設定をどのように見つけるのか、指針が必要。
参考文献 #
[2]: 白川悠太, 岡谷貴之:ディープボルツマンマシンを用いた線画の修復, 情報処理学会研究報告, Vol. 2013-CVIM-187, No. 30, pp. 1-6, 2013.