二次割当問題¶
二次割当問題は、以下のような問題です。
\(N\) を正の整数とする。\(N\) 個の工場建設候補地に \(N\) 個の工場を建設することを考える。それぞれの工場は、どの建設候補地に建設されても良い。どの 2 つの工場にも、それらを行き来するトラックが走っており、その輸送量はあらかじめ分かっている。輸送量 x 走行距離の和を最小化するにはどうすればよいか。
応用として、集会の座席表を仲が良い人同士が近くなるように決定することなどが考えられます。
定式化¶
\(N\) 個の工場建設候補地を 土地 \(0\), 土地 \(1\), ..., 土地 \(N-1\) と表記し、\(N\) 個の工場を工場 \(0\), 工場 \(1\), ..., 工場 \(N-1\) と表記します。また土地 \(i\) と土地 \(j\) の距離を \(D_{i, j}\), 工場 \(k\) と工場 \(l\) の間の輸送量を \(F_{k, l}\) とします。
変数¶
\(N \times N\) 個のバイナリ変数 \(q\) を用意し、\(q_{i, k}\) は工場 \(k\) を土地 \(i\) に建設するかどうかを表すことにします。
たとえば、\(q\) が以下のような値をとるとき、土地 \(0\) には 工場 \(3\) が建設されます。
工場 0 |
工場 1 |
工場 2 |
工場 3 |
工場 4 |
|
|---|---|---|---|---|---|
土地 0 |
0 |
0 |
0 |
1 |
0 |
土地 1 |
0 |
1 |
0 |
0 |
0 |
土地 2 |
0 |
0 |
0 |
0 |
1 |
土地 3 |
1 |
0 |
0 |
0 |
0 |
土地 4 |
0 |
0 |
1 |
0 |
0 |
制約条件¶
バイナリ変数テーブルのそれぞれの行と列には 1 となる値がちょうど 1 個である必要があります。したがって、各行各列に one-hot 制約をかけます。逆に、これらがみたされていれば、どの土地にどの工場を建設するかが 1 通りに定まります。
目的関数¶
目的関数は、工場と工場の間の輸送量 x 距離の総和です。これは \(q\) を用いて数式で表すと
となります。
数式¶
以上の定式化は、\(N\times N\) 個のバイナリ変数 \(q\) を用いて
と書くことができます。
問題の作成¶
Amplify SDK による定式化を行う前に、問題を作成しておきます。簡単のため工場の数 \(N\) を 10 とします。
import numpy as np
N = 10
土地間の距離を表す行列 \(D\) を作成します。土地はユークリッド平面上にランダムに生成します。距離行列は 2 次元の numpy.ndarray として作成します。名前は distance とします。
rng = np.random.default_rng()
x = rng.integers(0, 100, size=(N,))
y = rng.integers(0, 100, size=(N,))
distance = (
(x[:, np.newaxis] - x[np.newaxis, :]) ** 2
+ (y[:, np.newaxis] - y[np.newaxis, :]) ** 2
) ** 0.5
print(distance)
[[ 0. 33.121 60.44 53.852 31.385 71.61 12.042 60.208 76.609 90.211]
[33.121 0. 74.967 80.455 60.877 64.846 32.65 37.443 79.624 94.726]
[60.44 74.967 0. 31.575 41.012 44.011 49.82 68.25 28.284 35.511]
[53.852 80.455 31.575 0. 23.087 72.691 48.301 87.664 59.841 65.924]
[31.385 60.877 41.012 23.087 0. 71.197 28.284 75.895 65.863 76.059]
[71.61 64.846 44.011 72.691 71.197 0. 59.908 37.054 23.854 36.688]
[12.042 32.65 49.82 48.301 28.284 59.908 0. 52.154 64.637 78.39 ]
[60.208 37.443 68.25 87.664 75.895 37.054 52.154 0. 58.941 73.164]
[76.609 79.624 28.284 59.841 65.863 23.854 64.637 58.941 0. 15.133]
[90.211 94.726 35.511 65.924 76.059 36.688 78.39 73.164 15.133 0. ]]
工場間の輸送量を表す行列 \(F\) を作成します。2 次元の対称行列をランダムに作成し、名前は flow とします。
flow = np.zeros((N, N), dtype=int)
for i in range(N):
for j in range(i + 1, N):
flow[i, j] = flow[j, i] = rng.integers(0, 100)
print(flow)
[[ 0 86 63 44 7 66 32 73 51 45]
[86 0 69 96 53 18 32 59 58 62]
[63 69 0 53 14 6 26 28 70 52]
[44 96 53 0 52 88 65 71 66 82]
[ 7 53 14 52 0 11 51 22 13 33]
[66 18 6 88 11 0 68 16 9 81]
[32 32 26 65 51 68 0 51 31 36]
[73 59 28 71 22 16 51 0 64 21]
[51 58 70 66 13 9 31 64 0 48]
[45 62 52 82 33 81 36 21 48 0]]
Amplify SDK による定式化¶
Amplify SDK による定式化を行います。定式化において、どの 2 つのバイナリ変数からなる 2 次項も目的関数に現れるので、Matrix クラスを使うと効率的な定式化を行うことができます。
変数の作成¶
Matrix クラスを使用した定式化を行うためには、VariableGenerator の matrix() メソッドを使用して変数を発行します。
from amplify import VariableGenerator
gen = VariableGenerator()
matrix = gen.matrix("Binary", N, N) # coefficient matrix
q = matrix.variable_array # variables
q
目的関数の作成¶
上で作成した matrix は Matrix クラスのインスタンスであり、
の 3 種類のプロパティを持ちます。
quadratic は 2 次の項の係数を表す numpy.ndarray で、その shape は今回は (N, N, N, N) となっています。quadratic[i, k, j, l] は q[i, k] * q[j, l] の係数に対応します。つまり quadratic には quadratic[i, k, j, l] = distance[i, j] * flow[k, l] となるように 4 次元 NumPy 配列を設定する必要があります。
linear と constant はそれぞれ線形項の係数と定数項を表しますが、今回使用する目的関数には 2 次の項しか含まれないため、設定しません。
np.einsum("ij,kl->ikjl", distance, flow, out=matrix.quadratic)
制約条件の作成¶
変数の作成 で作成した変数配列 q の各行各列に one-hot 制約をかけます。
from amplify import one_hot
constraints = one_hot(q, axis=1) + one_hot(q, axis=0)
組合せ最適化モデルの作成¶
目的関数と制約条件を組み合わせて、モデルを作成します。
penalty_weight = np.max(distance) * np.max(flow) * (N - 1)
model = matrix + penalty_weight * constraints
制約条件に penalty_weight をかけているのは、制約条件に重みをつけるためです。今回使用するソルバーである Amplify AE においては、制約条件に適切な重みを指定しないと、ソルバーが制約条件をみたそうとするよりも目的関数を小さくする方向に動いてしまい、良い解を発見することができなくなってしまいます。詳しくは 制約条件とペナルティ関数 を参照してください。
ソルバークライアントの作成¶
Amplify AE を用いて組合せ最適化を実行するために、ソルバークライアントを作成します。Amplify AE に対応するソルバークライアントクラスは AmplifyAEClient クラスです。
from amplify import AmplifyAEClient
client = AmplifyAEClient()
Amplify AE の実行に必要な API トークンを設定します。
Tip
ユーザ登録を行うと、評価・検証目的に使える API トークンを無料で入手できます。
client.token = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
ソルバーのタイムアウト値を設定します。
import datetime
client.parameters.time_limit_ms = datetime.timedelta(seconds=1)
求解の実行¶
作成した組合せ最適化モデルとソルバークライアントを使用してソルバーの実行を行い、二次計画問題の解を求めます。
from amplify import solve
result = solve(model, client)
目的関数の値は以下のように表示できます。
result.best.objective
208123.38524292797
最適解における変数の値は、NumPy の多次元配列の形式で以下のようにして取得できます。
q_values = q.evaluate(result.best.values)
print(q_values)
[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]]
結果の確認¶
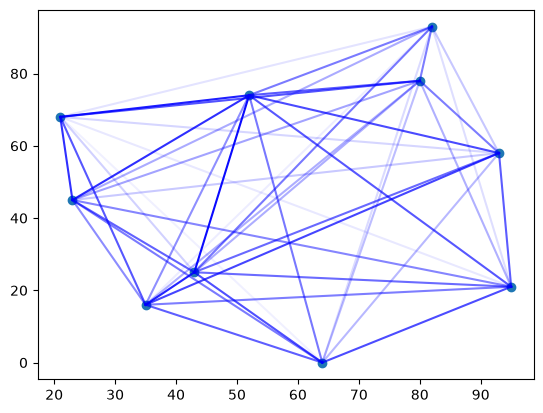
matplotlib を用いて結果を可視化します。
import itertools
import matplotlib.pyplot as plt
plt.scatter(x, y)
factory_indices = (q_values @ np.arange(N)).astype(int)
for i, j in itertools.combinations(range(N), 2):
plt.plot(
[x[i], x[j]],
[y[i], y[j]],
c="b",
alpha=flow[factory_indices[i], factory_indices[j]] / 100,
)